Our Technology
Replication Engine
A core differentiator of Stornamics is our globally distributed replication engine that provides asynchronous replication of your data across our products. The replication engine maintains a set of replication events detailing the change history of your database state over time, whether you're only using our cloud service, deploying our software in a high-availability configuration with hundreds of nodes across multiple on-premise sites, simply using it across multiple laptops or any combination of these.
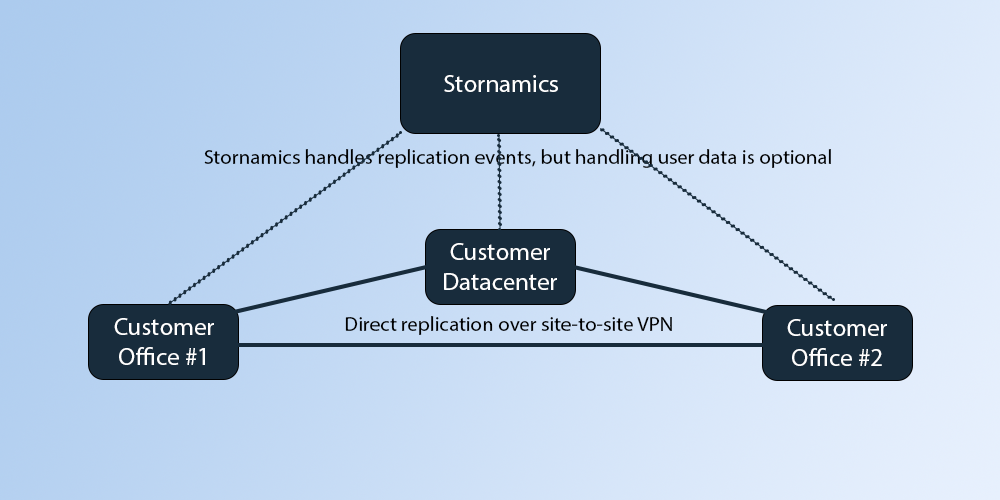
Configuration Management
In addition to the replication engine, the globally distributed Stornamics service handles service discovery, configuration, authentication and authorization of all the nodes. While the console allows the centralized administration of adding, removing and reconfiguration of all nodes, the nodes are self-aware of each other and can replicate data amongst themselves without the data needing to flow directly through our service. Though, organizations without direct communication between their sites or those that elect to allow laptops to maintain a copy will automatically sync up when connected to the internet.
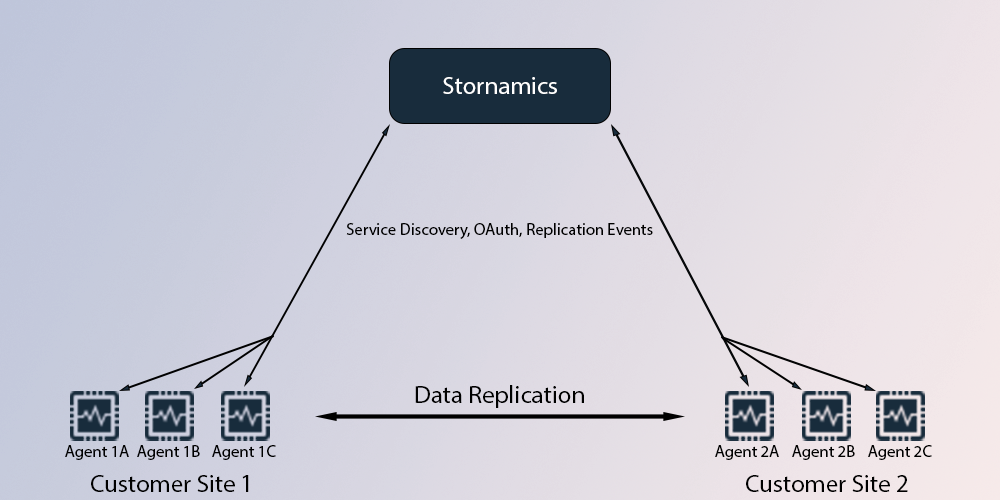
Sites & Zones
Customers have considerable flexibility in how they can structure their data. When getting started, you either start with a database in our managed service or you start with a local database, with that choice being your first site. Let's say a customer wants to use our time series database for logging to the cloud endpoint, but has two offices, in Seattle and Boston, to which they want the log data to be replicated for easier analysis. Seattle might be more limited in storage or needs, so they might set that site to only the last 30 days. In Boston, they want to ensure high availability for production needs and also have a third copy that is under load constantly due to analytics reporting, so they opt to create three zones.
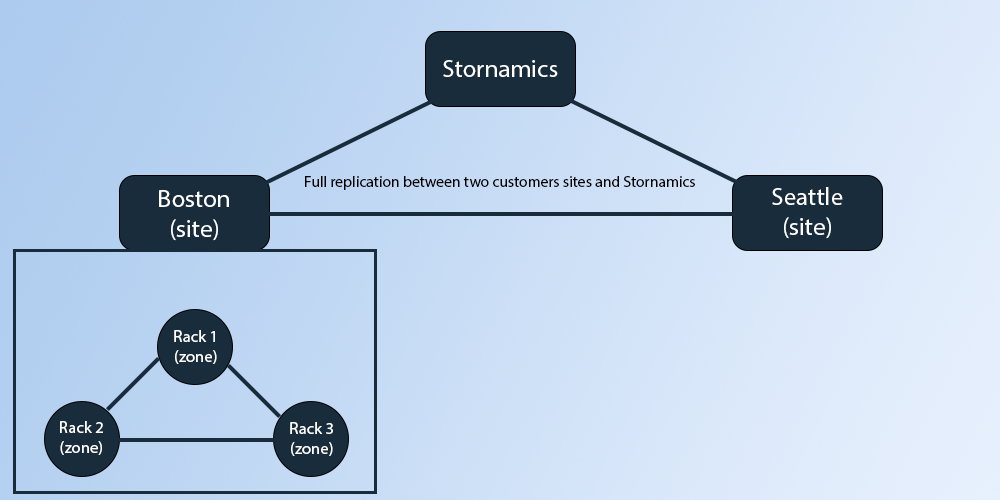
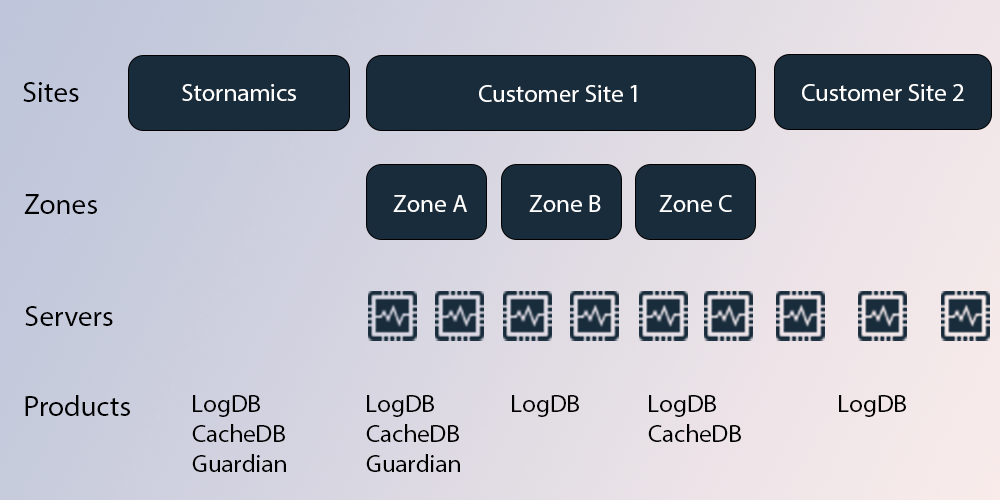
Hierarchy
While many customers likely won't use zones, we work with some organizations that will be growing into petabytes of data. To support these enterprise customers, each zone supports multiple servers to provide horizontal scaling of the data and we perform parallel querying of data across the zone as needed. As a separate use case, customers can use zones for deploying different products if they need varying levels of performance, compliance or other advanced use cases.
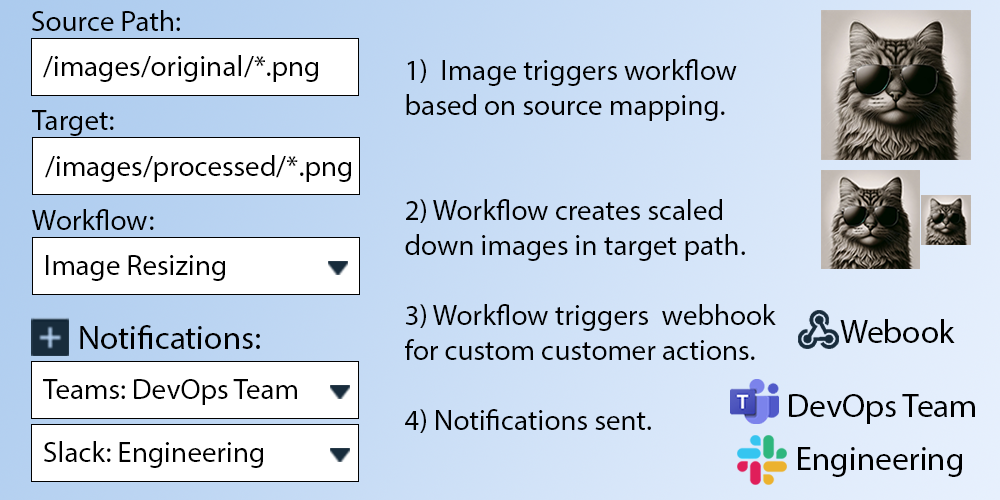
EdgeCompute
Our memory-optimized workflow engine can trigger actions based in real-time based on replication events. Customers can trigger actions based on a keyword match pattern on incoming data, a column of data exceeding a specific value, or the creation of object based on the file path. The workflow engine can eliminate the need for many organizations to build out pre-processing pipelines for their data and can reduce processing time and complexity. Like all of our services, this service can be run in the cloud or further customization can be done on-premise.
Guardian
If enabled, Guardian continuously scans incoming data for PII and security issues, ensuring your data remains safe and compliant. Additionally, automatic data classification can help you understand and organize your data effectively, enhancing security and efficiency.
